2025年10月30日配信
「FRONTEO AI Innovation Forum 2025」の初日となった2025年8月5日、第一三共株式会社 安全性研究所 グループ長の藤本和則氏による「毒性試験データベースの利活用とその課題~特に報告書テキストについて~」と題した講演が行われました。
10年以上にわたって毒性試験のデータベース構築に取り組まれてきた同社では、どのようにデータが蓄積され、AIが活用されているのか。講演では、実例をまじえながらその利活用と課題が紹介されたほか、FRONTEOとともに進められている「毒性学的解釈をデータに効率的にラベルするAIモデル」の開発についてもお話しいただきました。
ご講演者
 |
第一三共株式会社 安全性研究所 グループ長 藤本 和則 様 |
1. なぜ毒性試験データを蓄積するのか
新しい薬を開発する際、「効果がある」だけでは不十分です。人に投与しても安全かどうかを確認する必要があります。そのために実施されるのが毒性試験です。
毒性試験は、実施方法によって大きく2種類に分けられます。一つは、試験管内で細胞を使って化合物を評価する「in vitro(インビトロ)試験」。もう一つは、ラットやイヌなどの動物に化合物を投与して全身への影響を調べる「in vivo(インビボ)試験」です。
これらの試験では、開発中の化合物が人に対して意図しない悪影響を与えないか、副作用を起こさないかなどを確認するために、さまざまな検査項目を評価します。第一三共は、こうした毒性試験で得られた膨大なデータを10年以上にわたって蓄積してきました。
2. 化合物設計段階での毒性予測を実現
インビトロ試験のデータを活用した事例として、hERG阻害の予測について紹介します。hERGは心臓に存在しているカリウムチャネルの一種で、開発中の化合物が意図せずその働きを阻害すると、ヒトで致死性の不整脈が起きる可能性があります。そのため、開発の早い段階からhERG阻害を評価する必要があります。
hERG阻害については非常に多くのデータがあるため、そのデータを使ってAIや機械学習などを駆使して予測モデルを作っていきました。このモデルは現在、創薬化学者が化合物を設計する段階で活用されています。
このほかにも、肝臓の細胞を用いた試験から全身の毒性を予測するモデルの構築や、意図しない機能タンパク質への結合を評価する試験の効率化を蓄積された多くのデータを用いて実施しました。
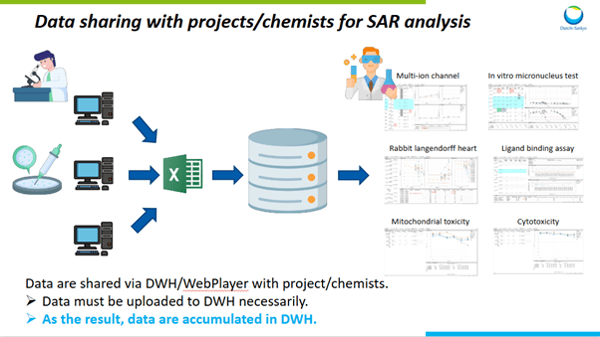
インビトロ試験においては、「自動的に」データが蓄積される仕組みが構築されています。具体的には、試験結果をデータウェアハウス(データベース)経由で、創薬化学者に共有するというフローを整備しています。
データベースに登録しなければ、プロジェクトチームや創薬化学者に結果をフィードバックできないため、必然的にインビトロデータがデータベースに蓄積していきます。
3. 「データ」はあっても「解釈」がない
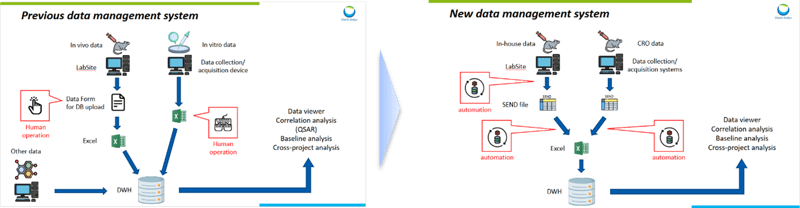
一方で、インビボ試験では、データの収集・蓄積に苦労しました。いくつかある理由の一つは、社内試験とCRO(外部委託機関)試験でデータ形式が異なり、統合が難しかったことです。
そこで、FDA(米国食品医薬品局)に臨床試験の実施を申請する際に作成・提出しなくてはいけない「SEND(Standard for Exchange of Nonclinical Data)」という標準フォーマットに着目しました。第一三共の社内試験では、インビボ毒性試験データを収集するシステムが使用されており、このシステムにはSENDファイルへの変換機能がありました。また、CRO委託試験ではFDAにSENDデータを提出するか否かに問わず、SENDファイルを作成するようにしました。これにより、社内試験データとCRO委託試験データを統合して蓄積することが可能になりました。
また、データを漏れなく蓄積するためには、インビトロ試験と同様に「自動的に」データが蓄積される仕組みを構築することが重要です。第一三共ではデータ収集システムから「自動的に」SENDファイルが生成され、そのデータが「自動的に」データベースに登録される仕組みを構築しました。
しかし、新たな課題が見えてきました。SENDファイルはあくまでもデータであり、毒性学的な解釈は含まれていません。
4. 数字だけでは判断できない──毒性学的解釈とは
インビボ毒性試験では、血液検査の数値変化や臓器の異常など、さまざまな「所見(観察された変化)」が記録されます。これらの所見を評価するには、三つの判断が行われます。まず、統計学的に有意な変化かどうか。次に、その変化が本当に化合物投与に起因したものか。さらに、その変化が毒性学的に意義があるかどうか。毒性学的に意義があるとは、その所見が何らかの有害な影響や異常を示すことを意味しており、毒性試験の結果解釈において非常に大事な判断になります。
毒性学者は知識、経験、種々の情報などに基づき一つ一つの所見についてその解釈を他の検査項目のデータも考慮しながら統合的に加えていきます。しかし、その解釈は報告書の中にしか記載されず、SENDデータの中には記載されていません。
具体例を見てみましょう。あるインビボ試験で、血液中の中性脂肪濃度が統計学的に有意にわずかに上昇したとします。データだけ見れば「異常あり」です。しかし報告書には「0.3 mg/kg/日での血液中中性脂肪濃度上昇は、用量依存性がないため、投与起因とは考えられない」と記載されています。統計学的には有意でも、同じ投与量での他の検査項目データ、他の投与量での血中中性脂肪濃度データ、検査項目の生物学的意義、所見の変化量などを考慮して毒性学的には意義がない、という判断です。
つまり、専門家による「この所見は本当に問題なのか」という判断は、SENDデータのように構造化されたデータには含まれていません。報告書に書かれたテキストの中にしか存在しないのです。
そこで、報告書に書かれた「解釈」を、検査項目の所見データと「自動的に」結びつける仕組みの構築という新たな挑戦を始めました。
5. FRONTEOとの協業からみえてきた実現可能性
そこで、データベース上で血液検査や病理の所見のデータを見ると、横に「毒性学的意義:有/無」という列が表示される。クリックすると報告書の該当箇所が表示され、判断の根拠を確認できる――そんな仕組みを「自動的に」作れたらと考えました。
この仕組みを実現するには、二つのAIモデルが必要です。
第一に、所見データと報告書のテキストを紐付けるモデルです。膨大な報告書の中から、その所見についての記載があるかどうかを判定します。
第二に、見つかった記載が毒性学的意義を示しているかどうかを判断するモデルです。
FRONTEOとの協業では、まず少数の報告書を使ってモデルの実現可能性が検証されました。
FRONTEOによって作られたモデルの性能を測定したところ、データと報告書のテキスト紐付けについては「F1スコア(精度の指標)」0.80〜0.90、「リコール(再現率)」0.67〜0.93という結果が得られました。最終的な毒性学的意義の判定についても、F1スコアは0.70〜0.88と、良好な結果が得られました。
ネガティブデータ(毒性学的意義がないケース)が非常に少ない場合には精度が低下するという課題も明らかになりましたが、現状、可能性が見えてきたと考えています。今後、データの数を増やすことでさらなる精度向上を図りたいと思います。
FRONTEOとの協業を通して、自然言語処理技術について非常に高いレベルを持っていることに加え、非臨床安全性研究の経験者がいて、同じ言語で相談できる点も、重要なポイントだったと感じています。

6. 過去の失敗を未来へ生かすために
インビトロ試験のデータは、予測モデルを構築して実際に活用することができました。一方、インビボ試験では、予測モデルを第一三共だけで作れるほど、たくさんのデータを蓄積するのは困難です。まずは報告書テキスト情報を含めたデータベースの構築に注力して取り組みたいと考えています。蓄積された過去のデータの二次利用は、未来のプロジェクトに必ず役立つと信じています。そのためにも所見データと結果解釈の紐付けはとても大事だと考えています。
今後は日本語で書かれた報告書への対応を進める考えです。
今回の検証に使用したモデルは英語の報告書をもとに構築されました。開発候補化合物が1つに絞り込まれてから実施されるインビボ試験の試験報告書は臨床試験実施に向けてFDAなどの規制当局に提出する必要があるため英語で詳細に記述されます。一方、創薬開発の初期段階で行われるインビボ試験は開発候補化合物を選択するために複数の化合物で実施されるため試験数が多く、そのため簡易的な報告書が日本語で作成されます。
日本語の簡易的な報告書でも英語の報告書と同様に、毒性学的意義や投与起因性の変化を「自動的に」見つけ出すことができるか。これが今の課題です。
※本稿は、2025年8月5日に行われた第一三共株式会社藤本和則氏の講演を、FRONTEO側で再構成したものです